
|
News Article
|
Published: 2015-06-01 in Technology
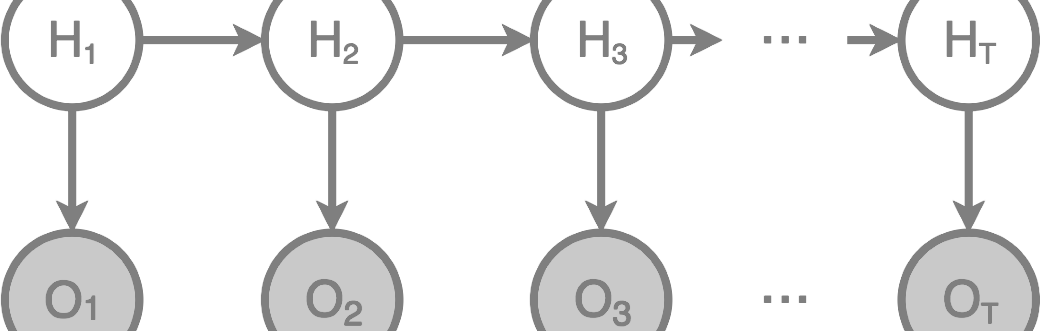
The first important milestone of the prototype implementation has been reached: we have implemented a state-of-the-art 'Part of Speech tagger' (POS-tagger). This means that the system is now at the level of current NLP-research and is actually at the forefront of development in this area.
|
The implemented POS-tagger is a Stochastic Tagger, based (in part) on previous research by Eric Brill (Brill-tagger) and our own developed model for Word Sequence Aggregation. What sets our POS-tagger apart from other efforts in this domain is the fact that our tagger does not use a previously tagged language corpus; it actually builds its own knowledge base (corpus) while it is being trained. The other discriminating feature is the fact that our POS-tagger uses a fairly small ruleset, whereas other taggers use large amounts of rules (sometimes hundreds) to be able to get to a usable percentage of recognition in a sentence. Furthermore, our tagger skips the step of tagging for grammar, instead words are directly tagged semantically. The tagger gives impressive results on very sparse data sets; our implementation reached around 90% correct tagging after being trained with just 400 sentences (ranging between six and sixteen words), adding up to just over 1000 words in total. |
Because of how the tagger works (without a previously tagged external corpus), it can recognize unknown words and has no problems with typos. Currently, we are still training the tagger to get to over 96% at least, but the best part is the fact that our tagger is actually learning recursively; eventually (around the 95-96% mark) we will no longer input corrections (supervised learning), but instead let the system figure out words it can not yet tag right away, at a later stage, when it contains enough information to do so. Although our POS-tagger is actually state-of-the-art in Part-of-Speech Tagging, it is only an infrastructural facility in our system. It is basically aimed at assisting the training of our ASTRID system. When the ASTRID-system has accumulated enough semantic knowledge, it will be able to infer rules for understanding language all by itself. |
|
NOTE: This news-article is presented here for historical perspective only. This article is more than two years old. Therefore, information in this article might have changed, become incomplete, or even completely invalid since its publication date. Included weblinks (if present in this article) might point to pages that no longer exist, have been moved over time, or now contain unrelated or insufficient information. No expectations or conclusions should be derived from this article or any forward-looking statements therein. |
| © 2024 MIND|CONSTRUCT |
- 2024-05-13 - Codedness platform does Clojure
- 2023-07-27 - A new 'Database paradigm' for ASTRID
- 2021-09-30 - ASTRID production code sets new training speed record
- 2021-05-20 - ASTRID code rewrite for production started
- 2017-12-08 - Major milestone: Knowledge Representation implemented
- 2015-10-30 - Beyond the XEROX benchmark POS-tagger
- 2015-03-02 - Prototype development started
- 2012-04-20 - Selecting the database platform for ASTRID
- 2012-04-19 - Basic development tooling selected